LynxPDF provides flexible and accurate OCR with low-quality image correction and 90+ language support. This ensures flawless data extraction, conversion, and digitization of all scanned documents and images.
Transform images & scanned business documents into searchable, editable, copyable, and printable PDFs while keeping the original layout and formatting.
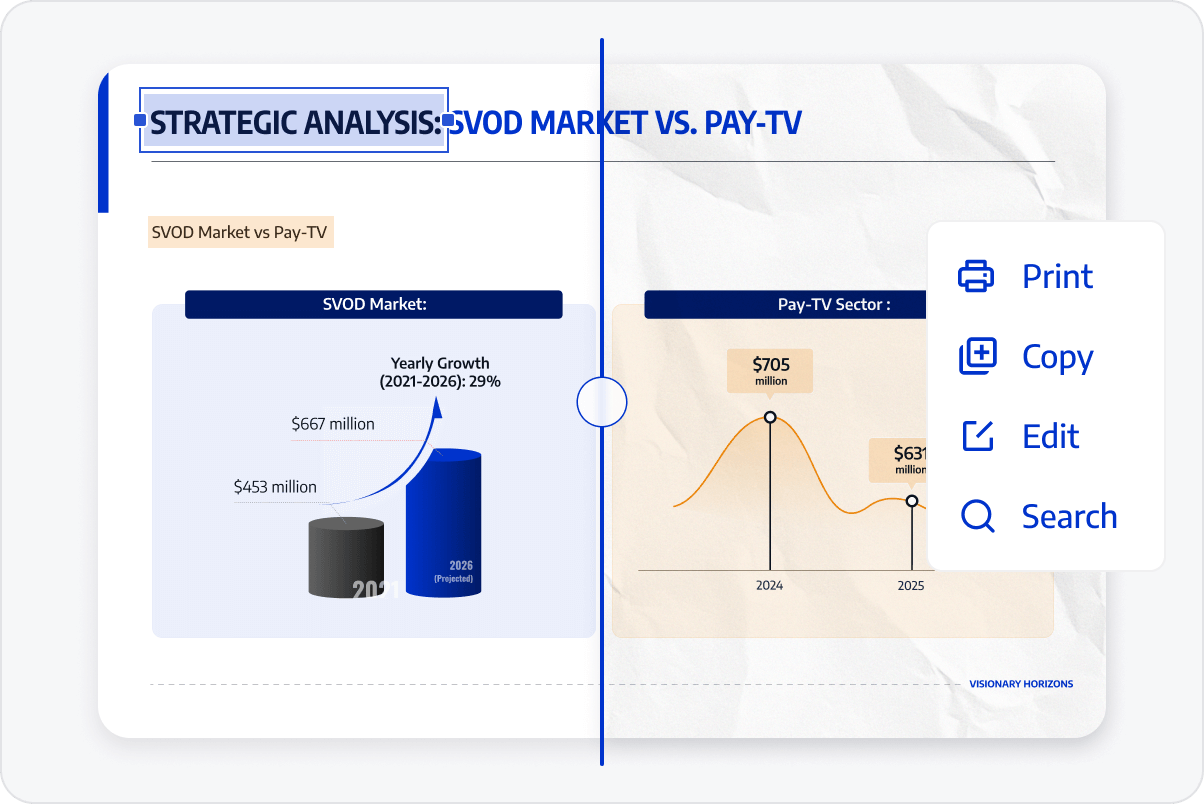
Convert Scans to Searchable PDFs
Search for keywords and locate information instantly. Recognize text within scanned files, allowing you to search for keywords and precisely locate specific information in long documents for quick retrieval.
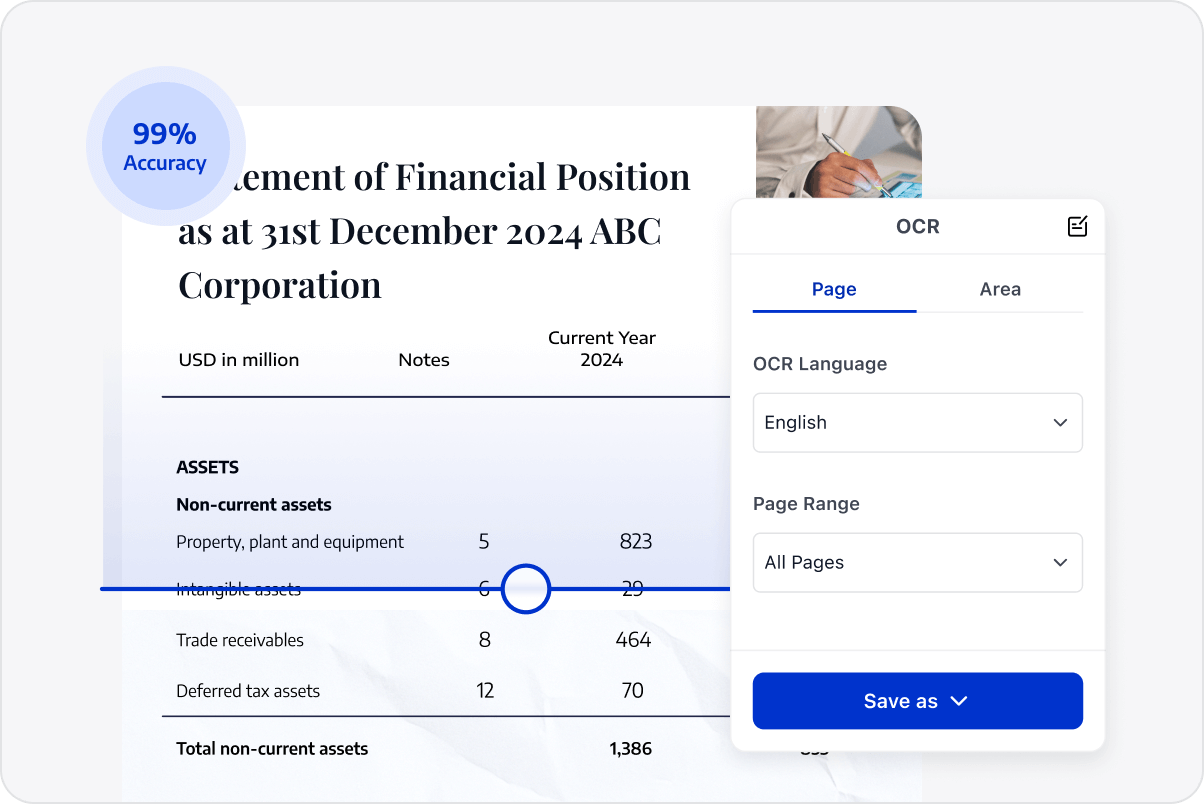
Optimization of Low-quality Images
Enhance the quality of low-resolution images with deskewing, alongside image enhancement technologies, improving the accuracy of data extraction and format conversion from images.
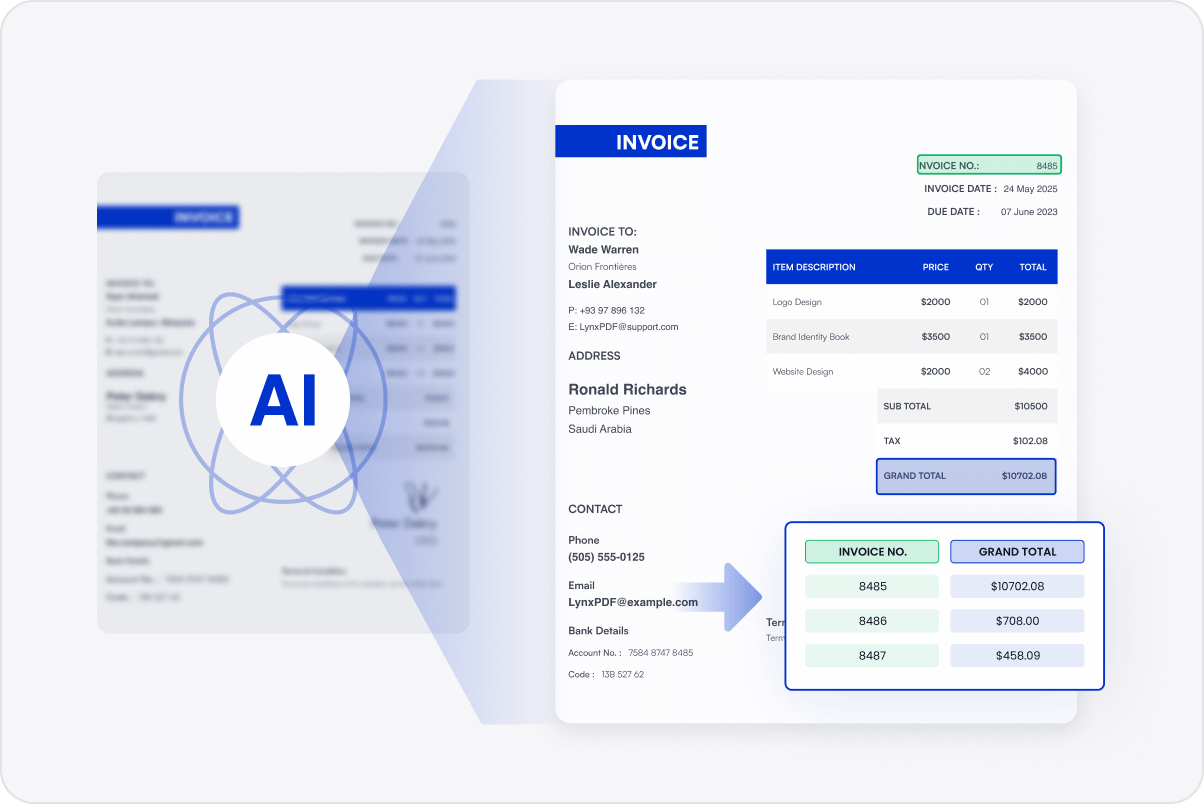
Smart Table Data Extraction
Accurately extract tabular data from scanned reports or invoices and export them to Excel, ready for data analysis with full structure and data integrity maintained.
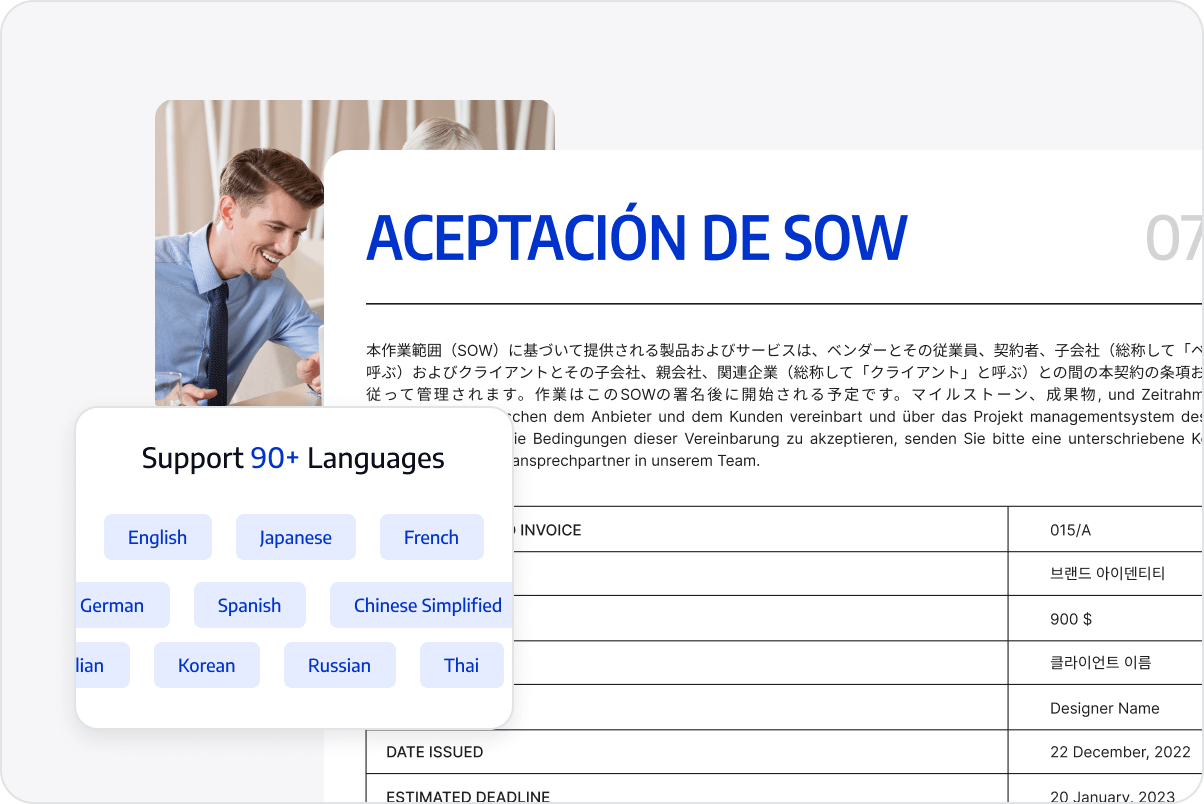
90+ Multilingual OCR Support
Recognize text in more than 90 languages, including English, Chinese, French, Russian, Arabic, Spanish, and German, meeting the needs of global enterprises. Automatic language detection and multi-language search additionally ensures smooth handling of documents.
Batch OCR Document Processing
One-click conversion of multiple scanned images or files into editable, interactive PDFs to accelerate company workflows and achieve a paperless office.
Access LynxPDF Expert Library
Forward-looking insights and strategic guides for enterprise document management.