


In every modern enterprise, information flows through countless documents—contracts, invoices, receipts, and reports. Yet many of these are still scanned PDFs,hard to search, edit, or integrate into digital systems.
OCR (Optical Character Recognition) bridges this gap by transforming static image-based files into editable, searchable, and machine-readable text. Without it, teams face inefficiencies, from finance departments manually entering invoice data to legal teams combing through unsearchable contracts.
As enterprises push toward digital transformation, PDF OCR has become more than a convenience—it’s a critical foundation for automation, compliance, and productivity. This article explores how OCR reshapes real-world business workflows and what makes the best OCR software essential for modern organizations.
How PDF OCR Powers Financial, Legal, and Archival Automation
PDF OCR technology transforms static files into searchable, usable data—helping enterprises improve accuracy and workflow efficiency.
1. Streamlining Financial Workflows with Invoice OCR and Receipt Scanning
For finance teams, the burden of manually entering invoice or expense data is both time-consuming and error-prone. With invoice OCR and OCR receipt scanners, companies can automatically extract data such as vendor names, amounts, and tax IDs directly from PDF documents.
These OCR tools convert image-based PDFs into structured formats like JSON or CSV, which can then be seamlessly integrated with ERP systems via API connections. The result is a fully automated financial workflow—reducing manual input, improving accuracy, and accelerating reconciliation.

With advanced enterprise PDF OCR, teams can process thousands of invoices in batches, maintaining consistent accuracy and compliance across every financial record.
2. Enhancing Legal and Contract Management with Searchable OCR PDF
Legal teams often deal with hundreds of scanned contracts and NDAs that are not searchable or editable, making it difficult to locate key clauses or verify terms. Through OCR technology, organizations can turn scanned documents into searchable, editable formats such as Word or a searchable PDF.
Once digitized, these contracts become fully accessible—enabling text search, clause extraction, and version comparison—dramatically reducing the time spent on legal review. This capability not only enhances productivity but also helps ensure audit readiness and regulatory compliance, critical for legal and compliance departments managing large document volumes.
3. Building a Searchable Knowledge Archive with Enterprise PDF OCR
Knowledge management is often overlooked in digital transformation. Many organizations still store decades of archives, reports, and research materials as image-based PDFs—making them hard to search, index, or reuse. With enterprise-grade OCR, these legacy documents can be transformed into fully searchable and machine-readable PDFs, allowing teams to retrieve information instantly. For enterprises aiming to strengthen information governance, OCR is not just a convenience—it’s a foundation for digital continuity.
Choosing the Right OCR Solution for Enterprise Workflows
As digital transformation accelerates, enterprises rely on accurate OCR to turn scanned and image-based documents into usable, searchable data. Yet many solutions still struggle with low-quality scans, multilingual files, and large-scale workloads.
LynxPDF 1.6.5 closes these gaps. With enhanced image optimization, auto-alignment, region-specific OCR, and seamless conversion, it delivers a faster, more accurate, and enterprise-ready OCR engine. The sections below outline how these upgrades improve real-world document workflows.
1. Advanced Image Enhancement & Automatic Optimization
Low-quality scans remain a major blocker in enterprise workflows. LynxPDF 1.6.5 introduces an upgraded enhancement engine that automatically improves clarity—reducing blur, noise, shadows, and color distortion in real time. It adjusts contrast, sharpens text, and removes artifacts without manual retouching, making OCR more accurate even on poor originals.

Image Source: Pixabay
For teams that handle signed contracts, archived files, or legacy scans, this delivers cleaner inputs and consistent results with far less manual effort.
2. Automated Image Rectification for Perfect Alignment
Scanned pages often arrive skewed or distorted. LynxPDF 1.6.5 fixes this automatically by detecting misalignment and correcting rotation and perspective. The system outputs properly aligned pages ready for precise OCR—critical for accuracy-sensitive sectors like law, finance, and healthcare.
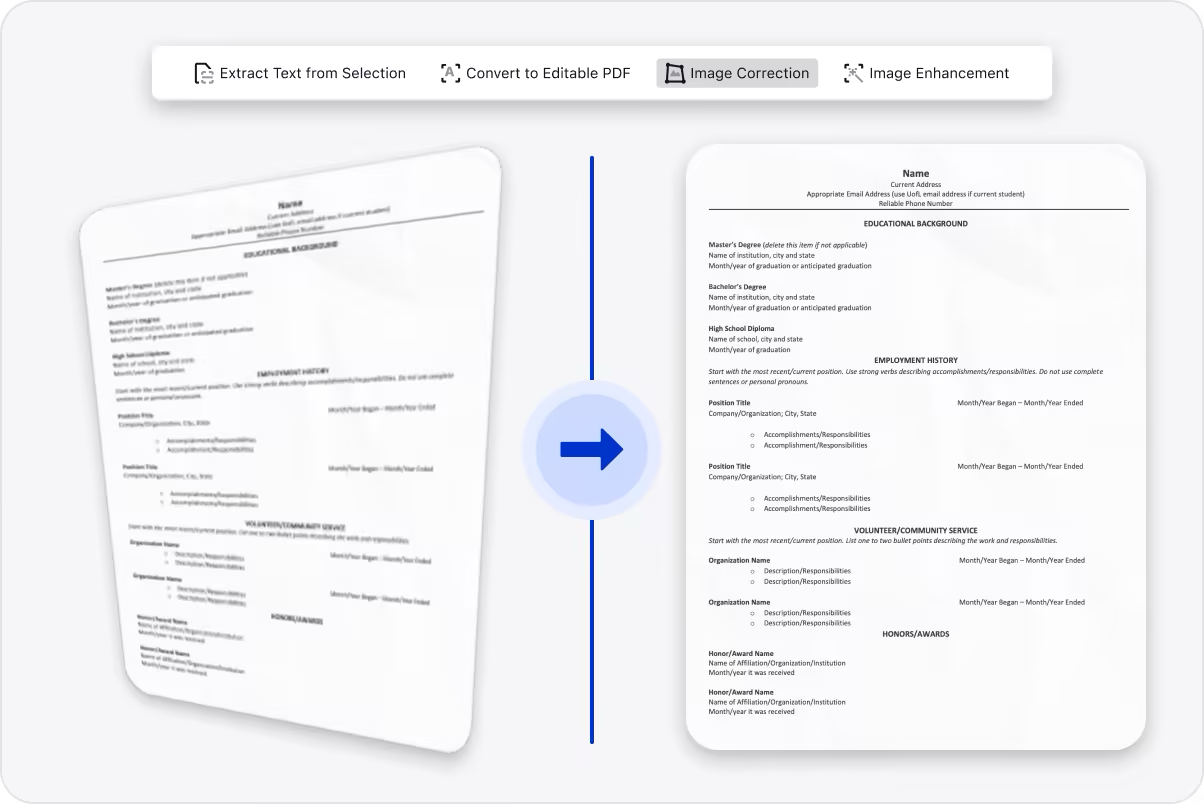
Auto-alignment removes the need for manual adjustments and ensures dependable OCR quality across single pages or large batches.
3. Precision OCR for Targeted Extraction
Many teams don’t need full-page OCR—they need specific data. LynxPDF 1.6.5 supports region-based OCR, letting users extract only what matters (tables, signatures, figures, key paragraphs).
This speeds up processing, avoids unnecessary data, and boosts efficiency—ideal for finance teams extracting tables, product teams capturing specs, or operations teams processing long manuals.
4. Seamless OCR-to-Document Conversion
A common frustration among enterprise users is discovering that “PDF-to-Word doesn’t work”—the converted file opens, but the text is still not editable. In most cases, the issue isn’t the converter itself; it’s the source document. Many PDFs are actually image-only scans, meaning they contain no real text for traditional conversion tools to extract. Without OCR, even the best converters can only reproduce a picture of the page rather than reconstruct usable content.
LynxPDF 1.6.5 solves this problem at the root. By integrating a full OCR engine directly into the conversion workflow, it can recognize text, tables, diagrams, and layout structures within scanned PDFs before rebuilding them into editable Word, Excel, or PowerPoint files. This ensures that even image-based contracts, invoices, and technical documentation become fully editable—eliminating manual retyping and reducing document turnaround time.
5. High-Volume Batch OCR for Scalable Operations
Enterprises often process hundreds or thousands of documents. LynxPDF’s batch OCR handles large queues automatically, producing searchable or editable outputs at scale.
This reduces manual workload, accelerates turnaround time, and maintains consistent quality—ideal for archives, monthly financial reports, or compliance documentation. Organizations can quickly convert paper-heavy workflows into searchable digital repositories.
6. Multilingual OCR for Global Business
Global operations require multilingual accuracy. LynxPDF 1.6.5 supports multiple languages—including English, Chinese, French, and more—through advanced deep-learning models. It can auto-detect or manually select languages, ensuring reliable extraction even in mixed-language datasets.

Image Source: Pixabay
This empowers enterprises working with international contracts, cross-border financial records, or multilingual customer documents to maintain a unified, consistent workflow worldwide.
In an era where document volumes continue to grow and workflows become more automation-driven, LynxPDF 1.6.5 focuses on exactly that—delivering consistent accuracy, stable performance, and workflow-ready outputs that teams can depend on. Improved processing efficiency helps organizations accelerate workflows, minimize manual effort, and build scalable, data-driven systems
Unlocking Business Value with Enterprise PDF OCR
Enterprise PDF OCR is more than a technology—it’s a strategic enabler for intelligent document processing. By automating manual entry, enhancing data accuracy, and securing digital workflows, businesses can unlock the full potential of their document assets.
For organizations exploring OCR deployment or enterprise automation, LynxPDF provides the perfect balance of accuracy, compliance, and integration flexibility.
👇Click below to try LynxPDF for free and experience how secure, seamless PDF OCR can redefine your team’s productivity.




